
Introduction
“Dirty data in, dirty analytics out”
Traditional data sources such as, SQL Server Warehouse or raw file feeds, tend to contain dirty data, which is often in a raw form and needs cleansing and massaging. In this stage, you need to check the health and state of data to transform it into a useful clean output to be stored in the model.
You can check health of the columns manually or use Power Query Editor’s below out of the box features:
Column Quality – Gives you a quick health overview of all the columns in the table

Column Profile – Detailed statistics of a selected column

Once you have done initial data quality check, your next step is to plan a series of transformations. This step can be overwhelming as Power Query Engine offers over 400 transformation tools, however, if you have a clear agenda, it’s not hard to find the right button on the GUI.
Below are 6 essential data cleansing rules that you can use as a go to checklist:
NOTE: Although, below mentioned data cleansing techniques are explained in the context of Power BI, they very much apply to any other data analytics solution/tool, which requires data prep.
- Data Type Corrections
- Remove Duplicates
- Handle Errors or Nulls
- Round Up/Down
- Proper Labelling Of Tables and Columns
- Improve Text Quality with Trim & Clean
Let’s look into each rule in depth:
1. Data Type Corrections
Power Query Engine is smart enough to detect data type of all the incoming columns, however, the default data type might not be adequate for the task on hand. For examples, a ‘Date/Time’ column with granularity to milliseconds should manually be converted into ‘Date’, if only the date part is relevant. Similarly, all the KEY columns required for relationships, should be of type ‘Whole Number’ (64 bit Integer) for best model performance. Refer this to learn more about Power BI Desktop data types.
How to? Right-click on the column you want to change data type for, select ‘Change Type’ and the desired data type, in below case we have converted Date/Time to Date.
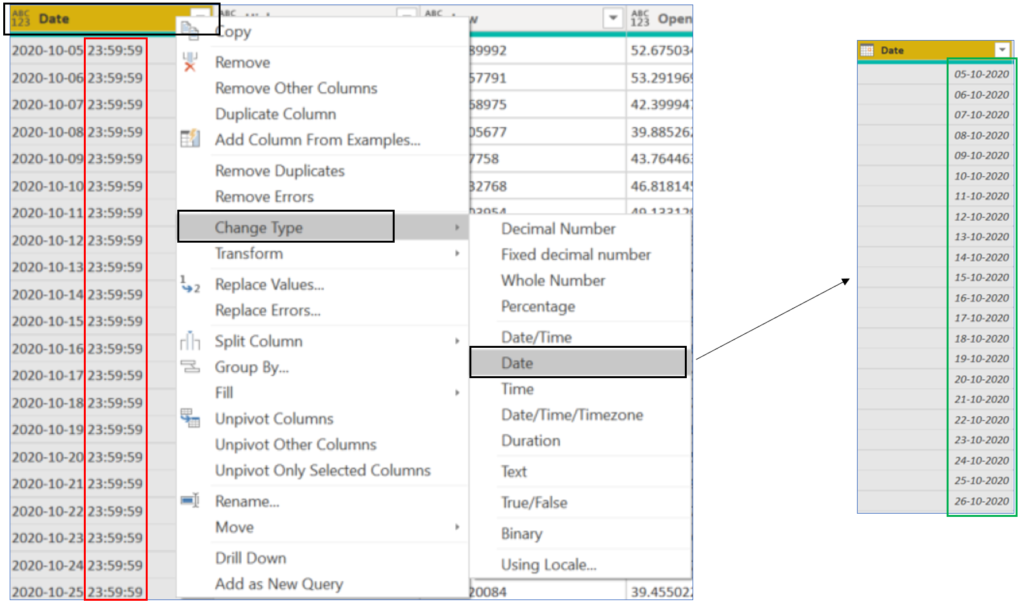
2. Remove Duplicates
Duplicate records can cause following issues:
- Consume additional storage in the model and can mess up DAX aggregations.
- When you join tables with duplicate records, the result merger can produce unexpected results.
- Duplicate records can cause nasty scenarios of Many to Many relationships in the model.
- Can result in inefficient storage compression by the VertiPaq Storage Engine.
How to? You can either remove duplicates at the table level or at the column level:
Table Level – Results in a table having distinct rows with all columns combined. Right-click on the top-left corner table icon and select ‘Remove Duplicates’
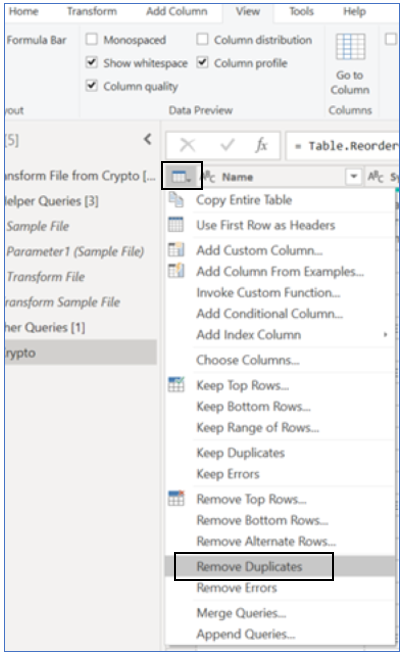
Column Level – Results in a column with distinct values, all other columns in the same table are not considered in this operation. Right-click on the column and select ‘Remove Duplicates’

3. Handle Errors or Nulls
You can choose to either remove/filter-out records having ERRORS/NULLS or replace them with a meaningful value, such as, average of the column, min/max values in the column or even a hard coded default value.
How to? Let’s look into below example, column [Marketcap] has NULL in one of the rows, we want to replace it with average of the column. First, right-click on the column header and select ‘Replace Errors’, next, enter ‘Value To Find = null’ and ‘Replace With = 1’. This will replace all NULLs in the column with hardcoded value ‘1’.

But, our purpose was to replace NULL rows with AVERAGE of the column. Unfortunately, ‘Replace With’ only accepts numbers, which is a limitation of the Power Query GUI. However, there is a workaround, we can edit the M-code formula and replace ‘1‘ with ‘each List.Average(#”Reordered Columns”[Marketcap])‘, below snapshot shows NULL finally replaced by a dynamic value, which is an average of the [Marketcap] column.

4. Round Up/Down
The decimal values can be rounded to 2 or even zero, if the resulting data analytics solutions will have context of aggregations and high level visualization of data.
How to? Right-click on the column you want to round, select ‘Transform -> Round -> Round…/Up/Down‘.
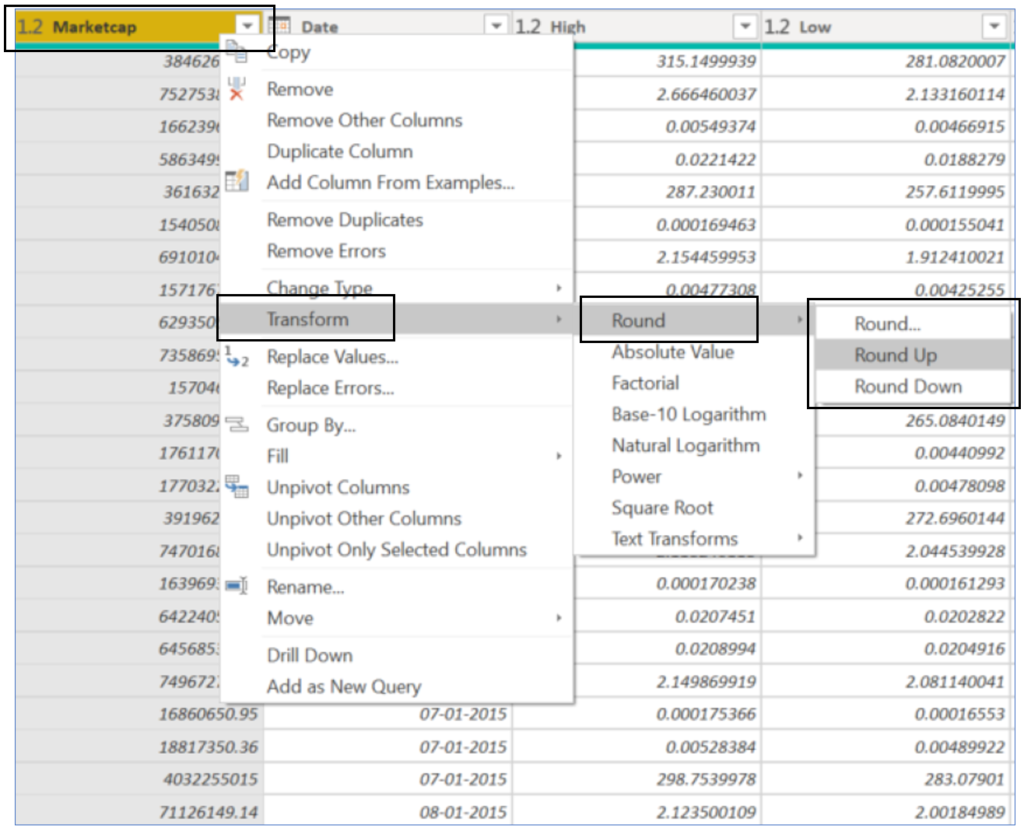
5. Proper Labelling Of Tables and Columns
The data sources, such as, SQL Server DB, often have long technical naming standards for schemas, tables and columns. Such nomenclature is useful for developers and admins, but, makes very little sense to the non-technical users of the Power BI data model, who will be consuming it as a Self-Service BI solution. Hence, you should always simplify names of the tables and columns, here is an example of SQL Server table named ‘[FinanceDatabase.dbo.DM_Consumption_Revenue_Fact]’, which can be simply renamed to ‘[Revenue]’ in Power Query. Same logic applies to column names.
How to? Right-click on the column you want to rename, select ‘Rename…‘, this will put the column header into editable mode.
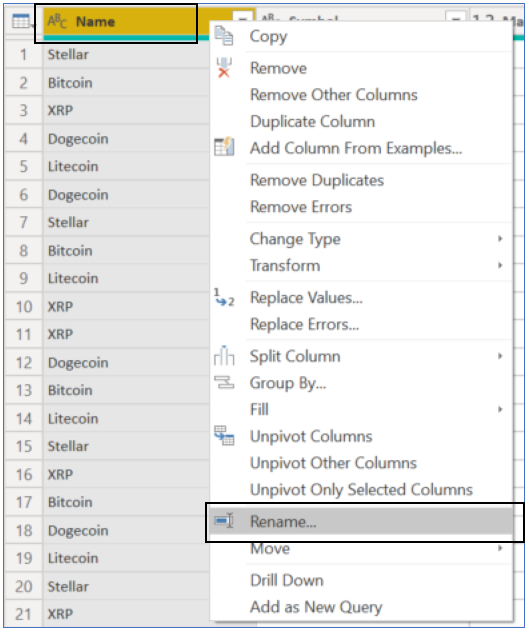
6. Improve Text Quality with Trim & Clean
Trim and Clean are two most important functions in Power Query to improve text quality in the data.
- Text.Trim removes all leading and trailing whitespaces from text.
- Text.Clean removes line feed and other control characters from text.
How to? Right-click on the column header you want to apply Trim or Clean, select ‘Transform -> Trim/Clean’.

Conclusion
Data cleansing plays a crucial role to feed high quality data into the data model, which produces meaningful insights in result. Data Cleansing stage occurs after you have connected to the data source and before you want to apply data shaping transformations. There are various methods and functions in the Power to improve quality of the data, these transformations depend on your state of the data and requirements on hand. However, you can apply above 6 data cleansing checklist to almost all type of use cases and tools, such as, Excel.
Next Step
After you are satisfied with the data quality produced by Data Cleansing transformations, your next step will be to shape the data to meet data modelling expectations.

Data evangelist with 11+ years of experience of serving a range of industries and clients worldwide using full stack BI. Here to talk everything data!

